Hello everyone!
What did you do this week?
I have almost completed the package list parser for python packages and made a checker for dpkg. I have also tried to improve checker support for python packages and hopefully won't hit false positives.Some insights on why package list parsers are made when we already have checkers
Package list parsers are much faster than the usual scanning with checkers.
Package list parsers takes an input, requiremens.txt, where the package names are listed and then use the pip freeze command to collect the installed python packages to find product name and version values and is then compared with the requirements.txt to filter out the needed packages. Then the vendor values are fetched from a CSV file containing vendor, product values. Finally the vendor, product, version values are used to query the CVE database.
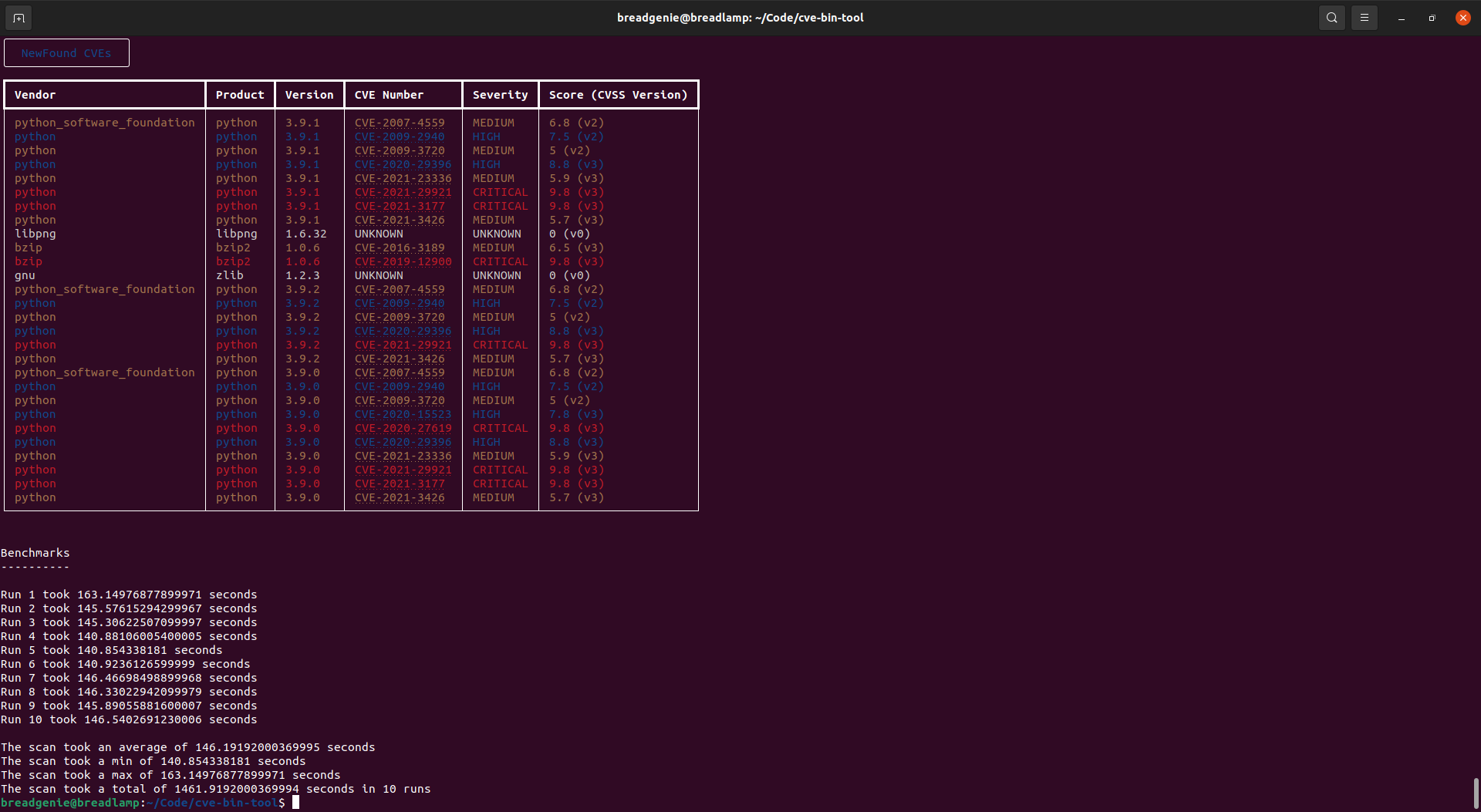
But the the checkers have to scan the files in a package one by one to find the necessary version strings and product name which consumes a lot of time.Benchmarks
That's ~7.3x faster than using checkers. :D (Scanning all my user installed python packages)Package list parsers can detect more products than checkers
Since package list parser doesn't depend on checkers it can detect more vendor-product pairs than scanning using checkers (but can hit some false positives too, eg: commonmark and zstandard).
Here 4 unique products are scanned while using checkers and 9 unique products (just the products with vendor-product pairs in the CVE database)while using package list parser.
{kind=link}
{kind=link}