Google Summer of Code 2021 Final Work Product
- Name: Bruno Messias
- Organisation: Python Software Foundation
- Sub-Organisation: FURY
- Project: A system for collaborative visualization of large network layouts using FURY
Abstract
We have changed some points of my project in the first meeting. Specifically, we focused the efforts into developing a streaming system using the WebRTC protocol that could be used in more generic scenarios than just the network visualization. In addition to that, we have opted to develop the network visualization for fury as a separated repository and package available here. The name Helios was selected for this new network visualization system based on the Fury rendering pipeline.
Proposed Objectives
- Create a streaming system (stadia-like) for FURY
- Should work in a low-bandwidth scenario
- Should allow user interactions and collaboration across the Internet using a web-browser
- Helios Network System objectives:
- Implement the Force-Directed Algorithm with examples
- Implement the ForceAtlas2 algorithm using cugraph with examples
- Implement Minimum-Distortion Embeddings algorithm (PyMDE) and examples
- Non-blocking network algorithms computation avoiding the GIL using the Shared Memory approach
- Create the documentation and the actions for the CI
- Stretch Goals:
- Create an actor in FURY to draw text efficiently using shaders
- Add support to draw millions of nodes using FURY
- Add support to control the opengl state on FURY
Objectives Completed
Create a streaming system (stadia-like) for FURY
There are several reasons to have a streaming system for data visualization. Because I am doing my Ph.D. in a developing country I always need to think of the less expensive solutions to use the computational resources available. For example, with the GPU’s prices increasing, it is necessary to share the a single machine with GPU with other users at different locations.
To construct the streaming system for my project we have opted to follow three main properties and behaviors:
- avoid blocking the code execution in the main thread (where the vtk/fury instance resides)
- work inside of a low bandwidth environment
- make it easy and cheap to share the rendering result. For example, using the free version of
ngrok
To achieve the first property we need to circumvent the GIL and allow python code to execute in parallel. Using the threading module alone is not good enough to attain real pralellism as Python calls in the same process can not execute concurrently. In addition to that, to achieve better organization it is desirable to define the server system as an uncoupled module from the rendering pipeline. Therefore, I have chosen to employ the multiprocessing approach for that. The second and third property can be only achieved choosing a suitable protocol for transfering the rendered results to the client. We have opted to implement two streaming protocols: the MJPEG and the WebRTC. The latter is more suitable for low-bandwidth scenarios [1].
The image below shows a simple representation of the streaming system.

The video below shows how our streaming system works smottly and can be easily integrated inside of a Jupyter notebook.
Video: WebRTC Streaming + Ngrok
Video: WebRTC Streaming + Jupyter
Pull Requests: * https://github.com/fury-gl/fury/pull/480
2D and 3D marker actor
This feature gave FURY the ability to efficiently draw millions of markers and impostor 3D spheres. This feature was essential for the development of Helios. This feature work with signed distance fields (SDFs) you can get more information about how SDFs works here [4] .
The image bellow shows 1 million of markers rendered using an Intel HD graphics 3000.

Fine-Tunning the OpenGl State
Sometimes users may need to have finer control on how OpenGL will render the actors. This can be useful when they need to create specialized visualization effects or to improve the performance.
In this PR I have worked in a feature that allows FURY to control the OpenGL context created by VTK
Pull Request:
- https://github.com/fury-gl/fury/pull/432
Helios Network Visualization Lib: Network Layout Algorithms
Case 1: Suppose that you need to monitor a hashtag and build a social graph. You want to interact with the graph and at the same time get insights about the structure of the user interactions. To get those insights you can perform a node embedding using any kind of network layout algorithm, such as force-directed or minimum distortion embeddings.
Case 2: Suppose that you are modelling a network dynamic such as an epidemic spreading or a Kuramoto model. In some of those network dynamics a node can change the state and the edges related to the node must be deleted. For example, in an epidemic model a node can represent a person who died due to a disease. Consequently, the layout of the network must be recomputed to give better insights.
In the described cases, if we want a better (UX) and at the same time a more practical and insightful application of Helios, the employed layout algorithms should not block any kind of computation in the main thread.
In Helios we already have a lib written in C (with a python wrapper) which performs the force-directed layout algorithm using separated threads avoiding the GIL problem and consequently avoiding blocking the main thread. But what about the other open-source network layout libs available on the internet? Unfortunately, most of those libs have not been implemented like Helios force-directed methods and consequently, if we want to update the network layout the Python interpreter will block the computation and user interaction in your network visualization.
My solution for having PyMDE and CuGraph-ForceAtlas not blocking the main thread was to break the network layout method into two different types of processes: A and B and communicate both process using the Shared Memory approach. You can more information about this PR through my following posts [2], [3].
The image bellow show an example that I made and is available at https://github.com/fury-gl/helios/blob/main/docs/examples/viz_mde.py
 Pull Requests:
Pull Requests:
MDE Layout: https://github.com/fury-gl/helios/pull/6
CuGraph ForceAtlas2 https://github.com/fury-gl/helios/pull/13
Force-Directed and MDE improvements https://github.com/fury-gl/helios/pull/14
Helios Network Visualization Lib: Visual Aspects
I’ve made several stuffs to give Helios a better visual aspects. One of them was to give a smooth real-time network layout animations. Because the layout computations happens into a different process that the process responsible to render the network was necessary to record the positions and communicate the state of layout between both process.
The GIF bellow shows how the network layout through IPC behaved before these modification
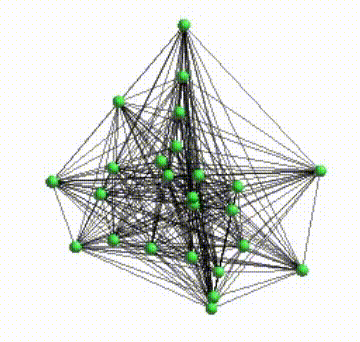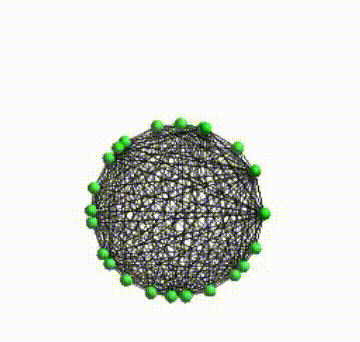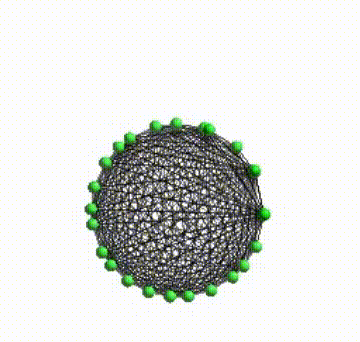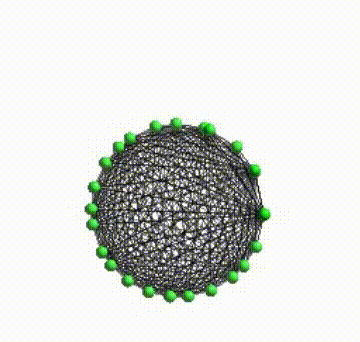
Bellow, you can see how after those modifications the visual aspect is better.

Pull Requests:
OpenGL SuperActors: https://github.com/fury-gl/helios/pull/1
Fixed the flickering effect https://github.com/fury-gl/helios/pull/10
Improvements in the network node visual aspects https://github.com/fury-gl/helios/pull/15
Smooth animations when using IPC layouts https://github.com/fury-gl/helios/pull/17
Helios Network Visualization Lib: CI and Documentation
Because Helios was a project that begins in my GSoC project It was necessary to create the documentation, hosting and more. Now we have a online documentation available at https://heliosnetwork.io/ altough the documentation still need some improvements.
Below is presented the Helios Logo which was developed by my mentor Filipi Nascimento.Pull Requests:
CI and pytests: https://github.com/fury-gl/helios/pull/5, https://github.com/fury-gl/helios/pull/20
Helios Logo, Sphinx Gallery and API documentation https://github.com/fury-gl/helios/pull/18
Documentation improvements: https://github.com/fury-gl/helios/pull/8
Objectives in Progress
Draw texts on FURY and Helios
This two PRs allows FURY and Helios to draw millions of characters in VTK windows instance with low computational resources consumptions. I still working on that, finishing the SDF font rendering which the theory behinds was developed here [5].
Pull Requests:
https://github.com/fury-gl/helios/pull/24
https://github.com/fury-gl/fury/pull/489

GSoC weekly Blogs
Weekly blogs were added to the FURY Website.
Pull Requests:
- First Evaluation: https://github.com/fury-gl/fury/pull/476
- Second Evaluation: TBD
Timeline
| Date | Description | Blog Link |
|---|---|---|
| Week 1 (08-06-2021) |
Welcome to my weekly Blogs! | Weekly Check-in #1 |
| Week 2 (14-06-2021) |
Post #1: A Stadia-like system for data visualization | Weekly Check-in #2 |
| Week 3 (21-06-2021) |
2d and 3d fake impostors marker; fine-tunning open-gl state; Shared Memory support for the streaming system; first-version of helios: the network visualization lib for helios | Weekly Check-in #3 |
| Week 4 (28-06-2020) |
Post #2: SOLID, monkey patching a python issue and network layouts through WebRTC | Weekly Check-in #4 |
| Week 5 (05-07-2021) |
Code refactoring; 2d network layouts for Helios; Implemented the Minimum distortion embedding algorithm using the IPC approach | Weekly Check-in #5 |
| Week 6 (12-07-2020) |
Post #3: Network layout algorithms using IPC | Weekly Check-in #6 |
| Week 7 (19-07-2020) |
Helios IPC network layout algorithms support for MacOs; Smooth animations for IPC layouts; ForceAtlas2 network layout using cugraph/cuda | eekly Check-in #7 |
| Week 8 (26-07-2020) |
Helios CI, Helios documentation | Weekly Check-in #8 |
| Week 9 (02-08-2020) |
Helios documentation; improved the examples and documentation of the WebRTC streaming system and made some improvements in the compatibility removing some dependencies | Weekly Check-in #9 |
| Week 10 (09-08-2020) |
Helios documentation improvements; found and fixed a bug in fury w.r.t. the time management system; improved the memory management system for the network layout algorithms using IPC | Weekly Check-in #10 |
| Week 11 (16-08-2020) |
Created a PR that allows FURY to draw hundred of thousands of characters without any expensive GPU; fixed the flickering effect on the streaming system; helios node labels feature; finalizing remaining PRs | Weekly Check-in #11 |
Detailed weekly tasks, progress and work done can be found here.
References
[1] ( Python GSoC - Post #1 - A Stadia-like system for data visualization - demvessias s Blog, n.d.; https://blogs.python-gsoc.org/en/demvessiass-blog/post-1-a-stadia-like-system-for-data-visualization/
[2] Python GSoC - Post #2: SOLID, monkey patching a python issue and network layouts through WebRTC - demvessias s Blog, n.d.; https://blogs.python-gsoc.org/en/demvessiass-blog/post-2-solid-monkey-patching-a-python-issue-and-network-layouts-through-webrtc/
[3] Python GSoC - Post #3: Network layout algorithms using IPC - demvessias s Blog, n.d.)https://blogs.python-gsoc.org/en/demvessiass-blog/post-3-network-layout-algorithms-using-ipc/
[4] Rougier, N.P., 2018. An open access book on Python, OpenGL and Scientific Visualization [WWW Document]. An open access book on Python, OpenGL and Scientific Visualization. URL https://github.com/rougier/python-opengl (accessed 8.21.21).
[5] Green, C., 2007. Improved alpha-tested magnification for vector textures and special effects, in: ACM SIGGRAPH 2007 Courses on - SIGGRAPH ’07. Presented at the ACM SIGGRAPH 2007 courses, ACM Press, San Diego, California, p. 9. https://doi.org/10.1145/1281500.1281665

